
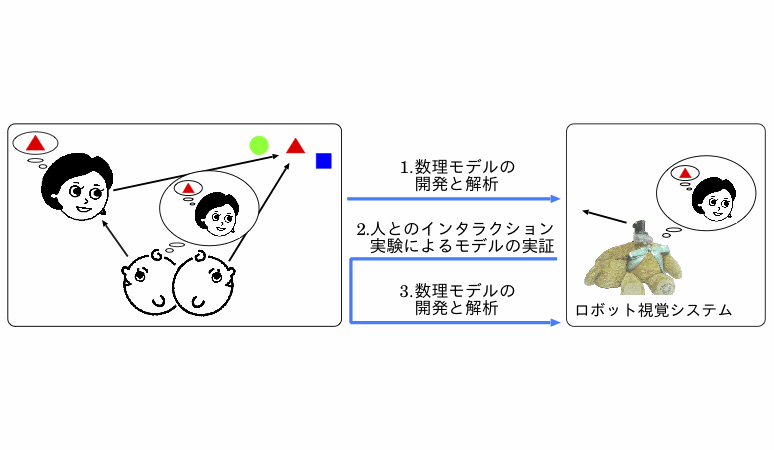
乳幼児が獲得する視覚的なコミュニケーション行動に共同注視がある.この行動は,親の視線が向く方向に子どもが視線を向ける行動と定義されているが,重要なのは,この行動が反射的な行動から意図的な行動に発達することである.本稿では,発達過程の初期段階で乳幼児が意図性を形成する過程をモデル化し,これをヒトとロボットのインタラクション実験によって検証する方法を提示する.

"2 者間会話環境時において,ノンバーバルな行動が互いに類似することが観察される.ノンバーバルな行動を意図的に同調させたとしても,同調された者が同調した者に対して好感度や信頼感をもつことが示されている.2者間会話環境時において表情の情報量は55%を占めており,表情を意図的に同調させることで社会的関係を促進することが可能だと考えられる.そこで本研究では表情の同調を促すために,同調を提示するインタフェースを提案する.最後に予備的実験を行い,今後の課題について述べる."

フレックスタイムのオフィスやサテライトオフィスにおける仕事など,異なる時間,異なる作業場所のメンバーと仕事をともにする環境の下では,互いの習慣や活動が不透明になりがちである.また,長時間作業しているメンバーの苦労をねぎらう,心配するといった,互いの習慣を把握している故のコミュニケーションも不足しがちである.そこで,我々は,習慣の不透明化の解決策として,行方履歴を記録し可視化することによって,メンバーの習慣を現在の行方と同時に提示することのできる電子行方表システム「DOCoCa」を開発した.我々は,電子行方表における行方履歴の可視化手法として,スパイラル表示を検討し実装を行った.また,システムを実際に稼働させ,システムが利用される頻度や利用のされ方について評価を行った.
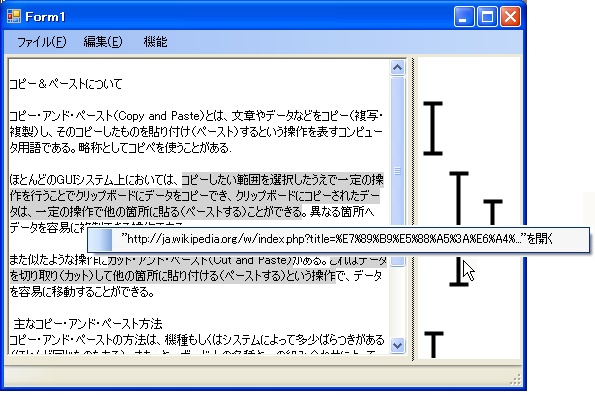
コピー&ペースト機能を使っていると,「ペースト後に編集したテキストをペースト時の状態に戻したい」,「コピー元のファイル内容を確認したい」など,コピー元ファイルに再アクセスする必要が生まれることがある.しかし,ペーストされたテキストに対して編集が加えられると,コピー元ファイルへの再アクセスが困難になってしまうという問題点がある.本研究ではこの問題点を解決するため,XMLタグを利用し,ペーストされたテキストに直接コピー元ファイルの情報を付与するコピー元情報管理手法を提案する.本手法では,ペーストされたテキストにどのように編集が加えられてもコピー元情報が残り,コピー元ファイルへのアクセスが可能である.さらに,コピー元表示機能を持つテキストエディタのプロトタイプについて述べる.
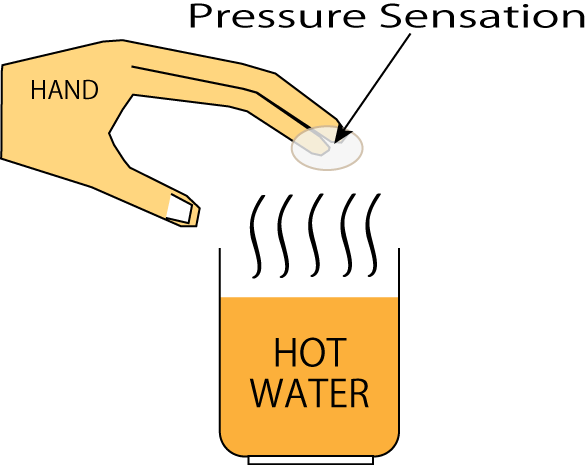
手を熱湯の上にかざしたとき、時として温度感覚以外に圧覚を知覚することがある。いくつかの理由が蒸気や、温度や、触覚受容器などのように存在しているであろう。この現象を利用することによって、新しい非接触触覚ディスプレーを提案することができるだろう。本稿では、各要素を切り離すことによって、この現象の理由の解明を試みる。

本研究の目的は,ユーザの現実の空間配置を再現することが重要であるか,および,その重要性はタスクに依存するかの実験的検証である.実験では協調型タスクと議論型タスクを用いて,同室環境(全被験者が同室にいる)と遠隔環境(被験者が遠隔の部屋に分かれる)の間でコミュニケーションの質と量を測定・比較した.その結果,協調型タスクでは距離感,積極性に関して遠隔環境が同室環境と同等のコミュニケーションの質を持ち,空間配置の再現の重要性が示された.一方,議論型タスクでは同等のコミュニケーションの質は得られなかった.このことから,次の2つの仮説が考えられる.仮説1:空間配置の再現の重要性はタスクに依存する.仮説2:空間配置の再現の重要性はタスクに依存しないが,要求される空間配置再現の品質がタスクごとに異なる.今後は追加実験を行い,どちらの仮説が妥当であるかを調べるとともに,仮説2が妥当であれば,様々なタスクに共通する空間配置再現の品質を得たい.
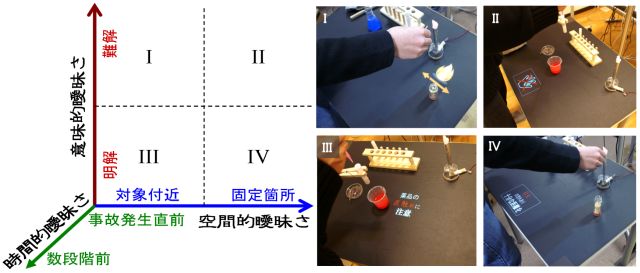
我々は,非熟練者が安全で独立できる方法で化学実験を支援するシステムについて検討を進めている.本稿では,「意味的曖昧さ」「空間的曖昧さ」「時間的曖昧さ」という3種の曖昧さを活用し,危険に関する情報の提示と危険回避や学習効果の関連性を明らかにするための実験を実施した.その結果,危険回避の支援については提案した手法が効果的に作用する曖昧さのレベル,学習効果については3種の曖昧さの効果に影響を与えうる要素が存在することを確認した.
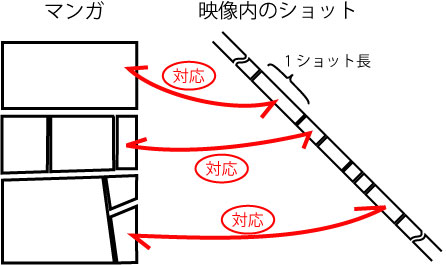
本稿では,映像内のショットと原作のマンガにおけるコマを対応付けることで,映像内のシーンの重要度が測定可能かどうか評価を行い,効果を確認した.また,マンガと映像の関係を「対応付け」という視点から論じ,要約映像の生成を試みた.

本稿では、多人数インタラクションから孤立した人を検出する方法を示す。具体的には,デジタルビデオカメラで撮影した立食形式パーティーの映像に発話区間・視線・身体方向といったアノテーションを付与し、会話における話し手・受け手・傍参与者といった参与役割を理解し,孤立者を浮かび上がらせることを試みる.この手法により、センシング技術に加担することによって,実際の多人数インタラクションの豊かさを見過ごす問題を取り上げ,従来型のセンシング技術を使ったインタラクション理解からのメディアデザインではなく、ハンドアノテーションからメディアデザインを導きだすという新たな方法を提案する。

立体ディスプレイの発展とともに,立体ディスプレイに表示された3Dコンテンツを操作する機会が増えると考えられる.しかし,3Dコンテンツの既存の操作手法は平面ディスプレイとマウスやスタイラスといった平面入力デバイスのためのものである.我々はこれまで立体ディスプレイのための操作デバイスとして円筒型マルチタッチインタフェースについて研究を行ってきた.本稿では複数の操作者が同時に使用することを想定した円筒型マルチタッチインタフェースにおける3D操作手法を提案する.また,これらの手法を利用して操作するアプリケーションを作成したので,そのアプリケーションについて説明し,利用シナリオを示す.